Getting raw audio from the Nicla Voice
If you’re working with a Nicla Voice and got stuck trying to grab its audio data, you’ve come to the right place. This is a fairly short article to document some of my learnings while attempting to collect audio data for training a ML model. While I managed to successfully transmit raw PCM data over serial, the resulting audio files are almost unusable due to limitations of Arduino’s serial transmission implementation.
As usual, I’ve uploaded working code onto my GitHub repository for your reference. Enjoy!
Working with NDP
Contrary to what the Arduino documentation suggests1, the PDM library cannot actually be used on the Nicla Voice. After digging through tons of documentation, source code and datasheets, I’ve come to the conclusion that the only way to grab audio data from the microphone is through the NDP class.
This was tricky to figure out and work with because the NDP class will only be initialised if all 3 required synpkg files on your flash are successfully loaded. It also means that your Nicla Voice will always boot with a bunch of debug information written to UART, regardless of whether you need to use the NN model.
// without these, you can't use your Nicla Voice at all:
NDP.begin("mcu_fw_120_v91.synpkg");
NDP.load("dsp_firmware_v91.synpkg");
NDP.load("ei_model.synpkg");
// in loop(), NN model runs immediately and starts printing into serial if there are match events
The solution is pretty simple. Send a b character from your Python script and use it to:
- stop inferencing, and
- control your device loop
// audio-serial.ino, loop()
while (1) {
int thisChar = Serial.read();
if (thisChar == 98) { // 'b' character
break;
}
}
# mic_serial.py
ser.write('b'.encode('utf-8'))
while True:
data = ser.readline() # clear the buffer
if data: break
Extracting and transmitting
Unlike the Nicla Vision, the only way you can access audio samples is through the NDP.extractData method:
uint8_t _local_audio_buffer[_samples] = { 0 };
while (_local_current_samples < required_samples) {
NDP.extractData(&_local_audio_buffer[read], &len);
if (len != 0) {
read += len;
if (read >= read_size * 2) {
Serial.write(_local_audio_buffer, read);
_local_current_samples += (read / 2);
read = 0;
}
} else {
delay(1);
}
}
Although the IM69D130 microphone documentation2 states that it produces PDM output, the nRF52832 SoC3 has decimation filters that automatically converts PDM data into PCM samples.
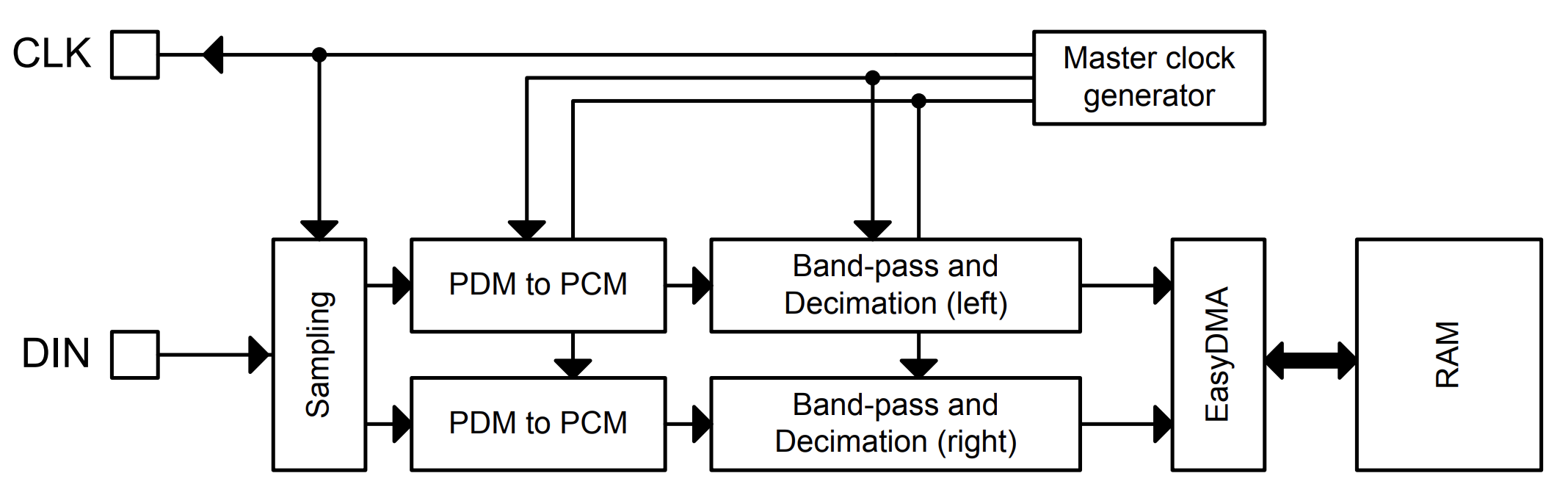
Decimation filters convert PDM data into PCM samples
Take note that NDP.extractData writes into a uint8_t array, which was strange at first because PCM data is usually in 16-bit signed integer format. I assumed that this was for ease of writing into a block device or transmitting over serial (one byte at a time).
Next, create and manage buffers sized according to the device’s audio chunk size and your desired sample length. Then, clear the extracted audio buffer whenever it reaches a certain size and just write it to the serial port.
Receiving audio samples
If you’re using my Python script, you’ll need to install the pyserial module to proceed. By default, the Nicla Voice’s microphone produces mono-channel 16-bit audio samples at a rate of 16000Hz, so just replicate the settings accordingly:
with wave.open('output.wav', 'wb') as wav_file:
wav_file.setframerate(16000)
wav_file.setnchannels(1)
wav_file.setsampwidth(2)
try:
while True:
# Read data from serial port, 1024 bytes at a time
data = ser.read(1024)
if not data: break
# received odd number of bytes
if (len(data) % 2) != 0:
data = data[:-1]
# 16-bit signed PCM samples (big endian)
samples = struct.unpack(f'>{len(data)//2}h', data)
# convert to little endian
wav_file.writeframes(struct.pack(f'<{len(samples)}h', *samples))
All that’s left to do is to unpack binary data from the serial port and write them into a .wav file. Because we’re receiving 16-bit data, getting the byte order (endianness) correct is the difference between an accurate audio file and static noise that will make your ears bleed.
Conclusion
As mentioned in the beginning of this article, I wasn’t able to use the audio samples for training in the end as the sound was choppy at best, and sometimes missing large chunks of audio. I’m not too sure what the reason is at this point, but I’m guessing this is primarily due to the Arduino platform’s implementation of its Serial.write method, which blocks the device if the serial buffer is full. It doesn’t help that the buffer is only 64 bytes large! It seems as if the microphone stops sampling whenever the device is blocked.
A viable solution is to replicate Edge Impulse’s way of sampling audio, which is to write audio data directly to flash memory first before transmitting it later. This would give us much higher quality audio, but sample length would be limited to available Flash memory.